안녕하세요 IT테크 인플루언서 프랭키입니다. 오늘은 빅데이터 분석의 핵심 툴인 하둡(Hadoop)에 대해서 알아보는 시간을 갖도록 하겠습니다. 최근 데이터는 4차 산업의 핵심 자원으로 간주되고 있습니다. 그런데 문제는 이 데이터의 양이 너무 방대하다는 것입니다. 이렇게 방대한 양의 데이터를 어떻게 효율적으로 처리하고 분석할 수 있습니까? 여기서 등장하는 게 ‘Hadoop’입니다. ‘하둡’은 우리가 살아가는 이 세상에 존재하는 방대한 양의 데이터를 처리하고 분석하는 데 중요한 역할을 하는 플랫폼입니다. 안녕하세요 IT테크 인플루언서 프랭키입니다. 오늘은 빅데이터 분석의 핵심 툴인 하둡(Hadoop)에 대해서 알아보는 시간을 갖도록 하겠습니다. 최근 데이터는 4차 산업의 핵심 자원으로 간주되고 있습니다. 그런데 문제는 이 데이터의 양이 너무 방대하다는 것입니다. 이렇게 방대한 양의 데이터를 어떻게 효율적으로 처리하고 분석할 수 있습니까? 여기서 등장하는 게 ‘Hadoop’입니다. ‘하둡’은 우리가 살아가는 이 세상에 존재하는 방대한 양의 데이터를 처리하고 분석하는 데 중요한 역할을 하는 플랫폼입니다.

자, 그러면 하둡이란 무엇인지, 왜 이렇게 중요한지, 그리고 어떻게 활용해야 하는지에 대해서 같이 알아보겠습니다. 1. 하둡 하둡이란? 자, 그러면 하둡이란 무엇인지, 왜 이렇게 중요한지, 그리고 어떻게 활용해야 하는지에 대해서 같이 알아보겠습니다. 1. 하둡 하둡이란?
인기글
냐, 카메라냐 - 완전 자율주행열쇠")
![[Case Study]5단계 자율주행을 위한 PNT 및 센서 융합 기술](https://nrms.kisti.re.kr/bitextimages/TRKO201700008849/TRKO201700008849_8_image_3.png "[Case Study]5단계 자율주행을 위한 PNT 및 센서 융합 기술")

![[대기오염의 영향] 미세먼지 황사 미세먼지.](https://img.etnews.com/photonews/2104/1404645_20210416181117_808_0001.jpg "[대기오염의 영향] 미세먼지 황사 미세먼지.")
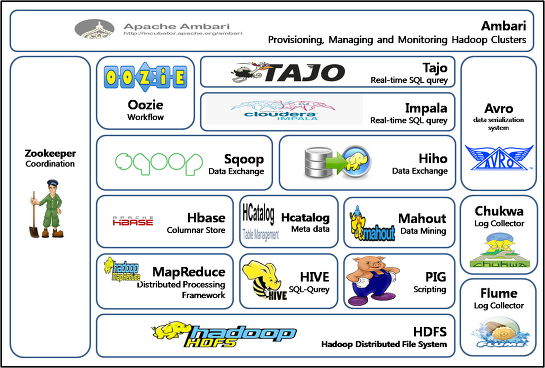
먼저 하둡이란 무엇일까요? Hadoop은 대용량 데이터를 처리할 수 있는 자바 기반 오픈 소스 프레임워크입니다. 여기서 ‘프레임워크’란 어떤 목적을 달성하기 위한 기본적인 구조를 의미합니다. 즉, 하둡은 방대한 양의 데이터를 효율적으로 처리하고 분석하기 위한 기본적인 틀을 제공하는 것입니다. 먼저 하둡이란 무엇일까요? Hadoop은 대용량 데이터를 처리할 수 있는 자바 기반 오픈 소스 프레임워크입니다. 여기서 ‘프레임워크’란 어떤 목적을 달성하기 위한 기본적인 구조를 의미합니다. 즉, 하둡은 방대한 양의 데이터를 효율적으로 처리하고 분석하기 위한 기본적인 틀을 제공하는 것입니다.
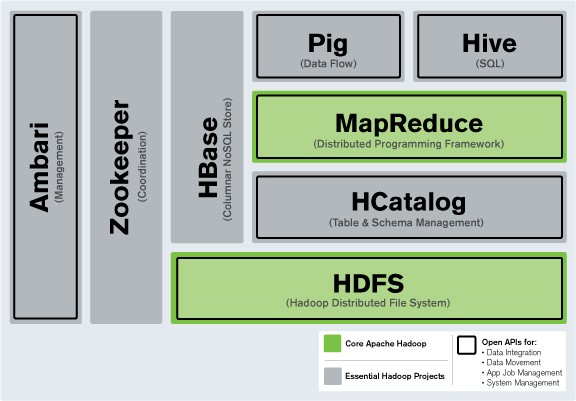
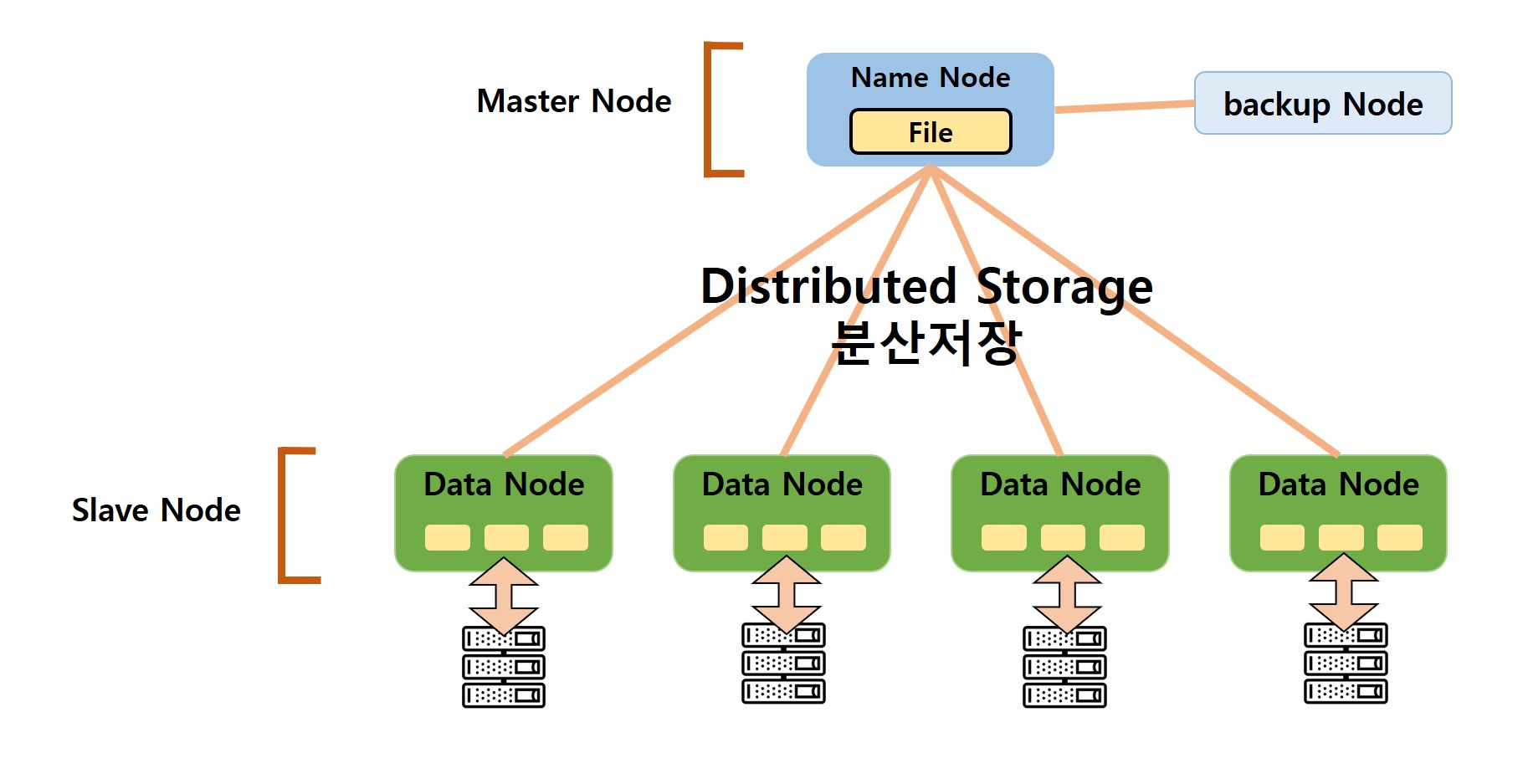
Hadoop의 핵심은 HDFS(Hadoop Distributed File System)와 MapReduce라는 두 가지 주요 컴포넌트로 구성되어 있습니다. HDFS는 대용량 데이터를 여러 대의 컴퓨터에 분산 저장하는 시스템을 의미하며, MapReduce는 이러한 분산된 데이터를 효과적으로 처리하는 프로그래밍 모델을 말합니다. 2. Hadoop Hadoop 데이터 분산 처리 Hadoop의 핵심은 HDFS(Hadoop Distributed File System)와 MapReduce라는 두 가지 주요 구성 요소로 구성되어 있습니다. HDFS는 대용량 데이터를 여러 대의 컴퓨터에 분산 저장하는 시스템을 의미하며, MapReduce는 이러한 분산된 데이터를 효과적으로 처리하는 프로그래밍 모델을 말합니다. 2. Hadoop Hadoop 데이터 분산 처리
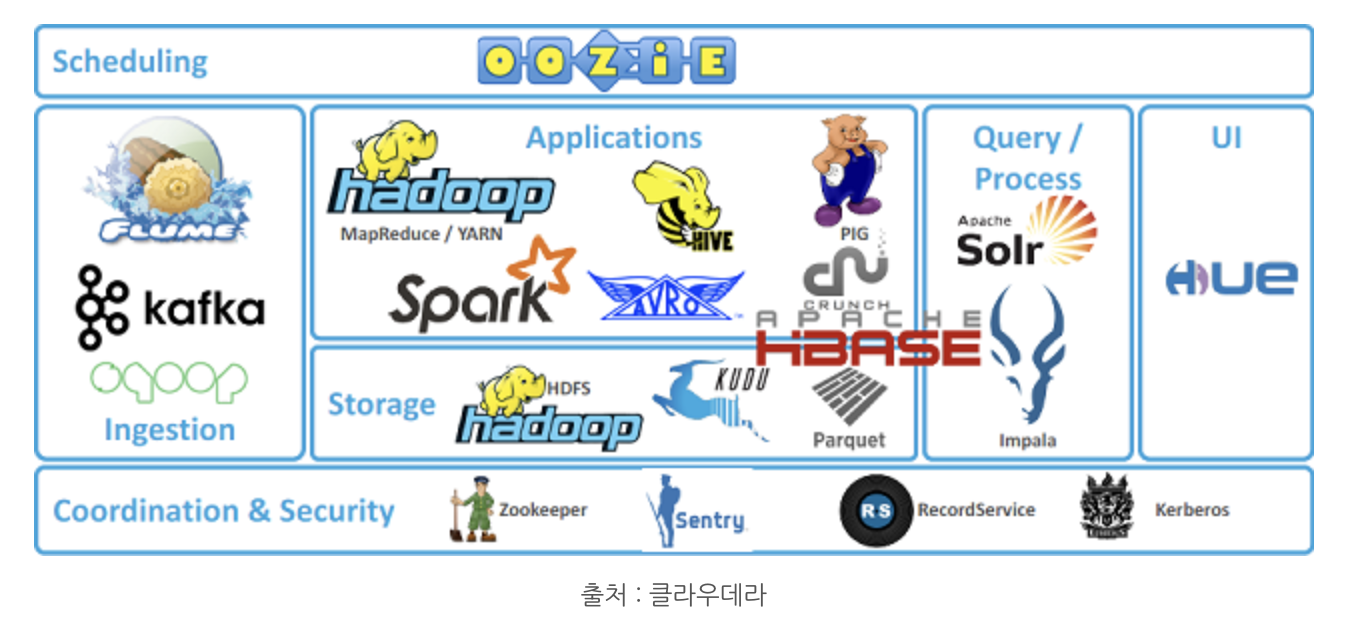
그러면 하둡의 핵심 구성요소인 HDFS와 MapReduce에 대해서 좀 더 자세히 살펴보겠습니다. 우선 HDFS는 하둡의 핵심적인 파일 시스템으로 대용량의 데이터를 안정적으로 저장하고 관리할 수 있게 해줍니다. HDFS는 여러 컴퓨터에 데이터를 분산 저장함으로써 단일 컴퓨터에서 발생할 수 있는 데이터 손실 문제를 예방하고 여러 컴퓨터에서 동시에 데이터를 처리함으로써 처리 속도를 향상시킵니다. 그러면 하둡의 핵심 구성요소인 HDFS와 MapReduce에 대해서 좀 더 자세히 살펴보겠습니다. 우선 HDFS는 하둡의 핵심적인 파일 시스템으로 대용량의 데이터를 안정적으로 저장하고 관리할 수 있게 해줍니다. HDFS는 여러 컴퓨터에 데이터를 분산 저장함으로써 단일 컴퓨터에서 발생할 수 있는 데이터 손실 문제를 예방하고 여러 컴퓨터에서 동시에 데이터를 처리함으로써 처리 속도를 향상시킵니다.
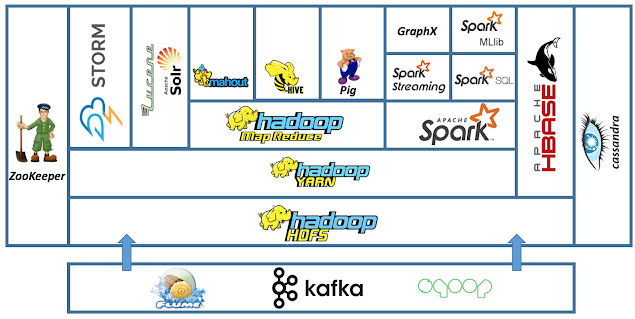
다음으로 MapReduce는 데이터를 처리하는 방법에 대한 프로그래밍 모델입니다. 맵(Map) 단계에서는 입력 데이터를 키와 값의 쌍으로 변환하고, 리듀스(Reduce) 단계에서는 맵 단계의 결과를 집계하여 최종 결과를 도출합니다. 이렇게 데이터 처리 과정을 단계별로 나누어 수행함으로써 복잡한 데이터 처리 작업을 쉽고 효율적으로 수행할 수 있습니다. 다음으로 MapReduce는 데이터를 처리하는 방법에 대한 프로그래밍 모델입니다. 맵(Map) 단계에서는 입력 데이터를 키와 값의 쌍으로 변환하고, 리듀스(Reduce) 단계에서는 맵 단계의 결과를 집계하여 최종 결과를 도출합니다. 이렇게 데이터 처리 과정을 단계별로 나누어 수행함으로써 복잡한 데이터 처리 작업을 쉽고 효율적으로 수행할 수 있습니다.
하둡을 이해하는 것은 중요합니다. 왜냐하면 우리는 빅데이터 시대에 살고 있기 때문입니다. 매일 수십억 건의 검색어가 입력되고 수조 건의 웹 페이지가 방문되며 수억 명의 사람들이 소셜 미디어를 활용하고 있습니다. 이러한 방대한 양의 데이터를 처리하고 분석하는 데 있어 Hadoop Hadoop은 그 중심에 위치하고 있습니다. 3. 하둡 하둡의 활용 사례 하둡을 이해하는 것은 중요합니다. 왜냐하면 우리는 빅데이터 시대에 살고 있기 때문입니다. 매일 수십억 건의 검색어가 입력되고 수조 건의 웹 페이지가 방문되며 수억 명의 사람들이 소셜 미디어를 활용하고 있습니다. 이러한 방대한 양의 데이터를 처리하고 분석하는 데 있어 Hadoop Hadoop은 그 중심에 위치하고 있습니다. 3. 하둡 하둡 활용 사례
그럼 Hadoop은 실제로 어떻게 활용될까요? 웹로그분석,소셜미디어데이터분석,기계학습,화상처리등다양한분야에서활용할수있습니다. 예를 들어 웹사이트의 로그 데이터를 분석하면 사용자의 행동 패턴을 이해하고 이를 기반으로 웹사이트를 개선하는 데 도움이 됩니다. 하둡을 활용하면 이러한 방대한 양의 로그 데이터를 효과적으로 처리하고 분석할 수 있습니다. 그럼 Hadoop은 실제로 어떻게 활용될까요? 웹로그분석,소셜미디어데이터분석,기계학습,화상처리등다양한분야에서활용할수있습니다. 예를 들어 웹사이트의 로그 데이터를 분석하면 사용자의 행동 패턴을 이해하고 이를 기반으로 웹사이트를 개선하는 데 도움이 됩니다. 하둡을 활용하면 이러한 방대한 양의 로그 데이터를 효과적으로 처리하고 분석할 수 있습니다.
또한 하둡은 오픈소스 프레임워크이기 때문에 누구나 무료로 이용할 수 있습니다. 이런 점에서 많은 기업들이 하둡을 활용해 자체 데이터 분석 솔루션을 구축하고 있습니다. 글을 다 쓰면서··· 또한 하둡은 오픈소스 프레임워크이기 때문에 누구나 무료로 이용할 수 있습니다. 이런 점에서 많은 기업들이 하둡을 활용해 자체 데이터 분석 솔루션을 구축하고 있습니다. 글을 다 쓰면서···
Hadoop에 대해 알아보는 이 과정에서 나는 빅데이터의 중요성을 새삼 느끼게 되었습니다. 우리가 살고 있는 이 세상은 데이터로 가득 차 있습니다. 이러한 빅데이터를 분석하고 효과적으로 이해하고 활용하는 것이 바로 하둡의 역할입니다. 그렇기 때문에 하둡을 이해하는 것은 빅데이터 시대에 살고 있는 우리 모두에게 중요한 일입니다. 오늘 글을 통해서 Hadoop이 무엇인지, 어떻게 활용되는지에 대한 전반적인 이해가 이루어졌다고 생각합니다. 다음 번에는 좀 더 깊이 있는 내용으로 다시 찾아뵙도록 하겠습니다. 그럼 모두 행복한 하루 보내세요! Hadoop에 대해 알아보는 이 과정에서 나는 빅데이터의 중요성을 새삼 느끼게 되었습니다. 우리가 살고 있는 이 세상은 데이터로 가득 차 있습니다. 이러한 빅데이터를 분석하고 효과적으로 이해하고 활용하는 것이 바로 하둡의 역할입니다. 그렇기 때문에 하둡을 이해하는 것은 빅데이터 시대에 살고 있는 우리 모두에게 중요한 일입니다. 오늘 글을 통해서 Hadoop이 무엇인지, 어떻게 활용되는지에 대한 전반적인 이해가 이루어졌다고 생각합니다. 다음 번에는 좀 더 깊이 있는 내용으로 다시 찾아뵙도록 하겠습니다. 그럼 모두 행복한 하루 보내세요!